The AI Trilemma for Indie Hackers: Balancing Cost, Speed, and Genius in Your LLM-Powered Product

Developing an AI product can feel like you’re standing at the edge of a vast frontier, eyes fixed on a horizon filled with opportunity. As indie hackers, we’re used to rolling up our sleeves and jumping into the fray. Yet when it comes to deploying Large Language Models (LLMs), one crucial puzzle emerges: How do you juggle the triple constraints of cost, speed, and reasoning quality without compromising your product’s core value?
This question—the AI Trilemma—defines your product’s trajectory. Optimize for raw intelligence, and you might burn through your budget. Focus on speed, and you may sacrifice depth. Aim for minimal cost, and risk delivering a subpar user experience. Despite the challenge, this tension also presents an opportunity to craft systems that carefully balance the needs of your users with the realities of your wallet.
Below, we’ll explore a refined and highly practical perspective on the AI Trilemma. You’ll find frameworks, an updated decision matrix, stories of illusion versus reality (in terms of speed and cost), and actionable steps for effectively managing your LLM infrastructure—without draining your runway.
1. The Refined Trilemma Matrix: Where Cost Meets Creativity
We often see an “Iron Triangle” whenever building products: cost, quality, and time (or speed). For LLM-based applications, this transforms into:
- Cost-Per-Call: How much each LLM request sets you back (considering both API and infrastructure).
- Response Speed (Latency): How quickly the user sees a result.
- Reasoning Depth (Quality): The complexity and accuracy of the AI’s output.
A Practical 2x2 Matrix for Indie Hackers
Let’s go beyond vague trade-offs and categorize your product features according to two major dimensions—Speed Sensitivity and Reasoning Complexity—while keeping a watchful eye on cost:
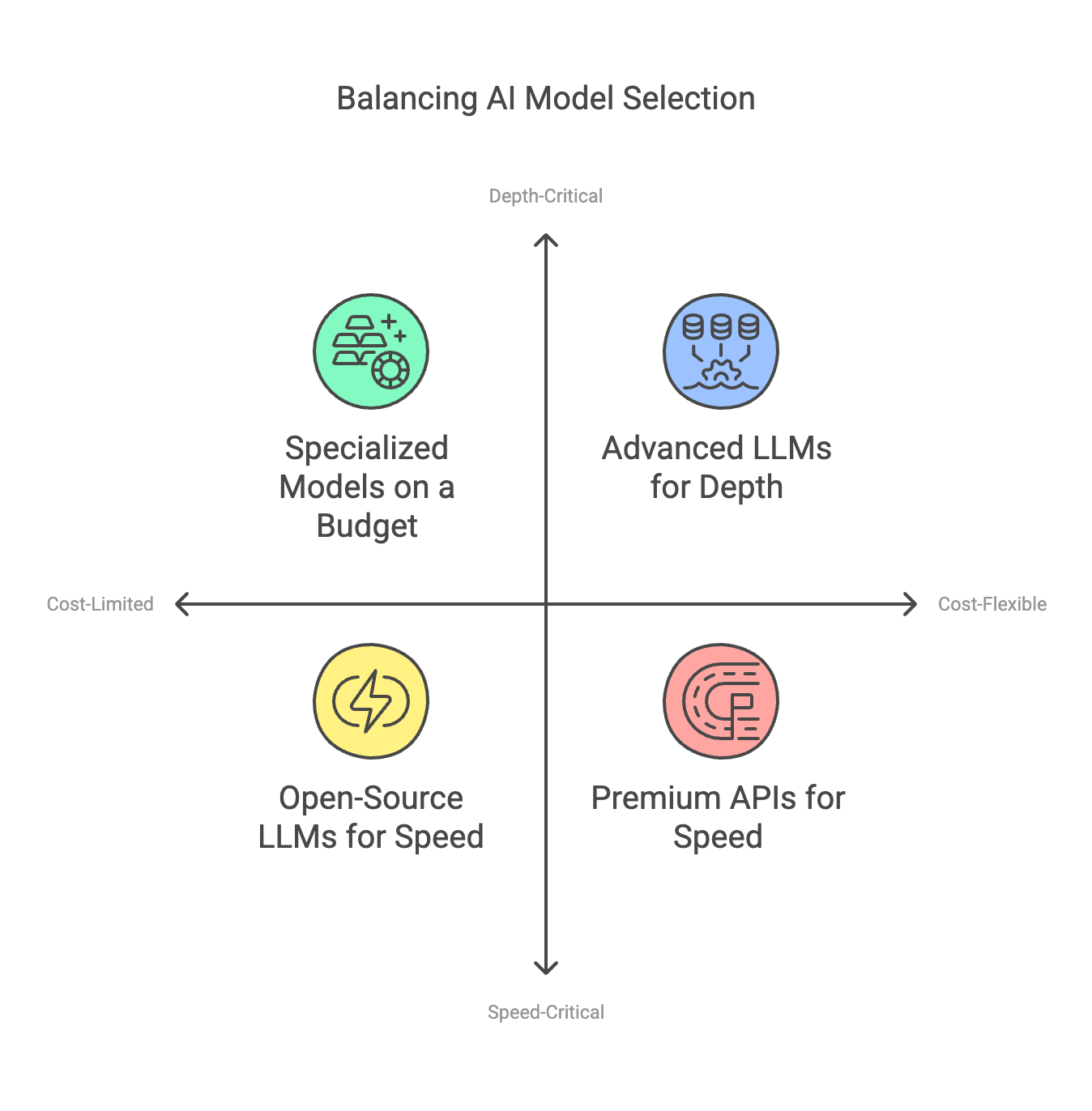
| Speed-Critical | Depth-Critical | |
|---|---|---|
| Cost-Limited | Real-Time, Minimally ComplexExamples: Swift translations, chat replies for casual apps | Budget-Constrained ComplexityExamples: Summaries, internal analysis with moderate detail |
| Cost-Flexible | High-Performance Quick InteractionsExamples: High-speed content generation with an emphasis on user delight | Premium High-ComplexityExamples: Personalized recommendations, advanced reasoning engines |
- Speed-Critical + Cost-Limited: You’re likely to choose smaller or open-source LLMs that are cheap and quick. This is ideal for high-frequency, real-time tasks.
- Speed-Critical + Cost-Flexible: You might be willing to pay more for high-performance hardware or premium APIs because user experience hinges on near-instant results.
- Depth-Critical + Cost-Limited: You need more nuanced output but still have a limited budget. You might queue tasks, batch requests, or find specialized models that give decent depth without sky-high costs.
- Depth-Critical + Cost-Flexible: You can unleash the full power of advanced LLMs (GPT-4o, Claude Sonnet, or fine-tuned specialized models) for tasks where depth is a must—even if that means paying more for inference.
Actionable Takeaway:
Instead of a single “one-size-fits-all” LLM choice, map each feature of your product to the right quadrant. You might realize your Q&A chatbot can run on a cheaper, smaller model, while a more advanced “analysis engine” feature uses a high-tier model but runs asynchronously to manage cost.
2. Pinpointing the Real Enemy: Reckless Burn Rate
Let’s face it: running out of money is the quickest way to kill your indie project—and API calls to advanced LLMs can rack up costs alarmingly fast. You need to be vigilant and strategic in your approach.
Common Cost Pitfalls:
- Excessive Token Usage: A large context window might seem appealing, but do you really need to feed entire books to the AI in every request?
- Unnecessary Calls: If you’re calling the model repeatedly without caching intermediate results, you’re lighting money on fire.
- Overestimating Speed Requirements: Real-time might be nice, but do users actually need sub-second responses for everything?
Cost-Saving Tactics:
- Caching and Memoization: Store previously computed results. If multiple users are asking similar questions or requesting the same summaries, a cache will dramatically cut costs.
- Dynamic Context Windows: Only feed the model the most relevant data. Trim your prompts and responses to the essential content.
- Session-Based Pricing Management: Implement daily or monthly usage caps. Offer paying users higher limits, while keeping free-tier usage under tight control.
- Hybrid Model Strategies: Use a cheaper model to handle routine tasks (initial filtering, classification) and escalate complex tasks to a premium model only when necessary.
Pro Tip: Always track your AI usage via analytics dashboards or logs. Real data beats guesswork every time. If you discover 80% of your requests are basic queries, it’s time to shift those to a less expensive solution.
3. Qstash Workflows: Asynchronous and Beyond
When cost is on the line, it’s tempting to reduce response times at all costs. However, forcing everything to happen in real time can become your budget’s worst nightmare. That’s where an asynchronous workflow system like Qstash Workflow truly shines—and it’s not just a message queue. Qstash offers parallel execution, in-sequence task orchestration, and more advanced workflow features that can dramatically improve your operational efficiency.
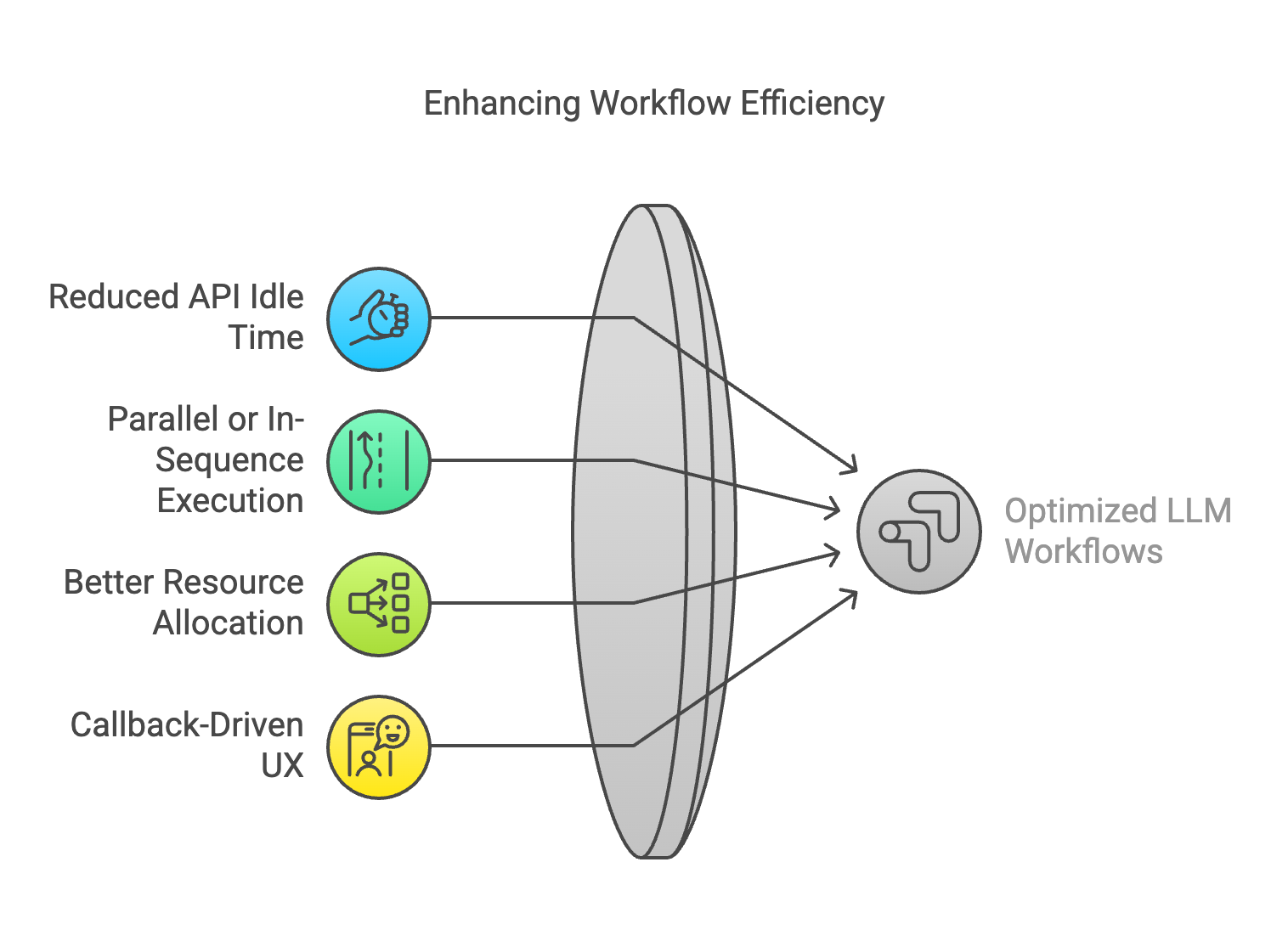
Key Benefits for Indie Hackers:
- Reduced API Idle Time: Instead of tying up your server or user’s browser for a long-running advanced LLM request, you enqueue the job or break it into a workflow with parallel or sequential steps.
- Parallel or In-Sequence Execution: You can define tasks that run simultaneously (e.g., partial sub-analysis) or in a strict sequence (e.g., step-by-step logic). This flexibility lets you optimize for your unique use case.
- Better Resource Allocation: Scale your background workers based on actual demand. You can pay for heavier compute only when tasks pile up, and scale down during off-peak times to cut infrastructure bills.
- Callback-Driven UX: Provide immediate feedback to the user (“Task started…we’ll email you when it’s done!”) instead of making them stare at a loading spinner.
How a Qstash Workflow Might Look
- Task Creation: A user requests a complex operation, like analyzing a large PDF.
- Workflow Definition: Qstash splits the request into multiple smaller tasks—e.g., “Extract PDF text,” “Summarize sections in parallel,” and then “Merge final summary.”
- Parallel or Sequential Execution: Some tasks run simultaneously for speed; others wait until prior steps complete for accuracy.
- Final Callback: Once the workflow finishes, Qstash calls back your app with final results.
This strategy manages user expectations and preserves your budget, because you’re not spinning expensive resources unless they’re truly required. It also opens doors for flexible pricing models, like “pay-per-analysis,” which can be more transparent for your customers—and keep your own spending in check.
4. The Illusion of Speed vs. The Reality of Cost
Perception is powerful. If users feel your application is fast, they’ll be more forgiving of waiting times, especially if those waits are masked by well-designed asynchronous flows and updates.
Techniques to Manage Perception:
- Progress Indicators: Instead of “loading…”, show stages of progress. Seeing steps like “Analyzing Document” or “Generating Summary” feels more reassuring than a static spinner.
- Partial Responses: For tasks like large text generation, you can stream partial outputs to the user in real time (or near real-time). People love seeing incremental updates.
- Multi-Tiered Response: Send a quick draft from a cheaper, faster model, then replace it with a more refined version from a deeper (but slower) model if/when that arrives.
These illusions can offer a better user experience and preserve budget by deferring or reducing your usage of pricier resources.
5. When Low Cost and High Speed Collide: Using Reflection in Agentic Workflows
A common misconception is that cheap, lightweight models simply can’t produce high-quality results. While it’s true that smaller models lack the power of GPT-4o-scale architectures, there’s a powerful technique to boost the quality of answers without paying for massive inference every time: Agentic Workflows with Reflection.
Reflection for Enhanced Reasoning
Instead of calling a small model once with a huge prompt and expecting brilliance, break the reasoning process into multiple steps, and let the model “reflect” on its own output. For instance:
- Initial Draft: The small model offers a quick first pass answer.
- Self-Critique: The same (or another small) model reviews that draft, identifies weaknesses or errors.
- Refinement: A final pass integrates the critique into a polished response.
This iterative approach, sometimes referred to as chain-of-thought prompting or self-reflection, can dramatically improve the coherence and thoroughness of smaller models’ outputs. You still enjoy lower per-call costs and faster inference than a massive LLM, but with a final result that approaches a higher quality bar.
Pro Tip: Tools like Qstash Workflow can coordinate these reflection steps in parallel or sequence. You gain a streamlined workflow that harnesses multiple calls to a cheaper model while still delivering a richer final answer.
6. Eyeing the Future: Knowledge Distillation, MoE, and Emerging Giants
For many indie hackers, open-source or emergent LLMs hold the promise of escaping recurring API fees. Historically, these smaller models (Llama, Phi-4, Mistral, etc.) haven’t matched the full reasoning power of GPT-4o or Claude Sonnet 3.5 level. But exciting research in knowledge distillation and mixture-of-experts (MoE) technology suggests we may soon get near-GPT-4o-level “genius” in 8B, 13B, or 33B parameter models.
- Knowledge Distillation: By systematically transferring a large model’s “knowledge” into a smaller one, you can get a fraction of the size with surprisingly strong performance.
- Mixture-of-Experts (MoE): Splitting the model into specialized “expert” sub-models, then routing queries to the relevant ones. This can drastically reduce the compute overhead needed for each request.
The Emergence of DeepSeek V3 & 405B MoE Architectures
New contenders like DeepSeek V3—a rumored 405B-parameter MoE system—are pushing the envelope of what’s possible. Some of these models promise competitive pricing for heavy-lifting tasks, thanks to the efficiency gained from selectively activating only parts of the model. For indie hackers, this could unlock:
- Near GPT-4o-level Accuracy: Without the typical GPT-4o-level price.
- Improved Scalability: You may only pay in proportion to how many “experts” you actually need, rather than a single massive block.
- Future-Proof Flexibility: As knowledge distillation advances, you can potentially host a 13B parameter “student” model that’s nearly as good as a 100B+ “teacher” model, dramatically reducing costs over time.
What This Means for You:
- Stay Informed: Keep an eye on open-source communities and preprint servers (e.g., arXiv) for developments in distillation, MoE, or specialized model releases.
- Try Smaller or Emerging Models: Experiment with open-source or new MoE-based LLMs on test environments. Track performance vs. cost in real scenarios.
- Plan for a Transition: If you rely heavily on expensive closed-source models now, consider a roadmap that involves gradually moving some features to a distilled or MoE-based alternative once it’s mature enough.
Breaking News:
DeepSeek R1 series is just released. It exceeds Claude Sonnet and O1-mini level with its Distillation Version in 2025/01/20.
7. Scaling Up (Without Breaking the Bank)
As your product grows, the last thing you want is for success to become your downfall. Suddenly you have more users, more queries, and more expensive calls to advanced LLMs.
Strategies for Sustainable Scaling
- Rate Limiting & Dynamic Pricing: Gently encourage heavy users to upgrade. Rate-limiting free tiers reduces excessive usage. Offer power users well-defined paid plans.
- Autoscaling in the Cloud: If you self-host or run custom inference endpoints (e.g., fine-tuned open-source models), leverage autoscaling policies that match capacity to demand.
- Fine-Tuning & Model Specialization: Sometimes, training a specialized model can reduce costs in the long run. A smaller custom model might handle your domain better than a large, general model—especially if you see repeated, domain-specific queries.
- Router Approach: Use a logic layer that sends trivial or known queries to a cached database or simpler LLM, preserving heavyweight calls for new or complex requests.
8. Making It All Work: Putting Theory into Action
Step 1: Start with a clear usage forecast. Estimate how many calls per day you might make and identify which portion of those calls require advanced reasoning.
Step 2: Implement a lean MVP of your product. Use a single, cost-effective model for everything at first—while building your asynchronous “Qstash workflow” in the background.
Step 3: Instrument your application with analytics. Measure how long calls take, how much they cost, and how often users rely on each feature.
Step 4: Iterate. Gradually introduce:
- Asynchronous Task Queues & Workflows (like Qstash, Celery, or RabbitMQ),
- Caching layers for repeated queries,
- Tiered LLM usage (smaller for quick tasks, bigger for complex tasks),
- Reflection or chain-of-thought sequences for smaller models that need a boost in quality.
Step 5: Optimize or pivot based on data. If your advanced analysis feature is rarely used, consider gating it behind a paywall or upgrading only a subset of users. If speed is crucial for your entire user base, you might allocate more budget for real-time inference and offset costs elsewhere (e.g., by limiting context windows or adopting open-source solutions).
9. A Final Word (and a Challenge)
No matter how clever your engineering or how optimized your system, the AI Trilemma—cost, speed, and reasoning quality—will never fully disappear. It’s a balancing act that requires continuous iteration and awareness of both your users’ real needs and your own financial constraints.
Yet, therein lies the advantage for indie hackers: you’re free to experiment, to pivot quickly, and to innovate in ways that bigger companies can’t. You can mix and match LLMs, refine prompt engineering, orchestrate reflection cycles, or even adopt open-source and emerging MoE solutions—whatever keeps you nimble and your budget intact.
The Challenge:
Don’t be afraid to launch with an imperfect balance. The key is to learn from real user behavior. Each data point guides you toward fine-tuning your approach—whether that means trimming prompt tokens, adding a second queue, or upgrading to a specialized model. The journey might be complex, but embracing the trade-offs, and turning them into opportunities, is exactly what makes independent creators so formidable.
Where do you stand on the cost-speed-quality spectrum?
Share your own triumphs and struggles in the comments or reach out directly. Together, as indie hackers, we can transform the AI Trilemma from a pain point into a launchpad for creative solutions that redefine what’s possible—even on a shoestring budget.
Stay Curious, Keep Building, and Hack On!