The AI Startup Edge: Leveraging Metrics, Fast Iteration, and Vertical Niches
Introduction: Where Should AI Startups Focus?
In the realm of artificial intelligence, having massive datasets is often touted as the key to success. However, for most resource-constrained AI startups, the real core lies in building strong evaluation capabilities. Whether a product can be continually improved depends largely on how effectively the team can evaluate a model, pinpoint issues, and gather data for future iterations.
You can visualize this virtuous cycle in four steps:
- Evaluation
- Attribution
- Improvement
- Data Collection
By continually iterating across these steps, an AI startup can achieve significant impact without necessarily having access to huge datasets. In this article, we will explore how to position a product correctly, why clear evaluation metrics matter, and how to leverage a niche approach to stand out in an intensely competitive landscape.
Core Product Positioning: User Expectations vs. Model Deliverability
Before diving into evaluation strategies, it’s essential to understand how a product can be positioned. For an AI startup, there are two primary dimensions to consider:
- Whether users have a clear expectation for deliverables (Yes/No)
- Whether a model alone can fully deliver on the task (Yes/No)
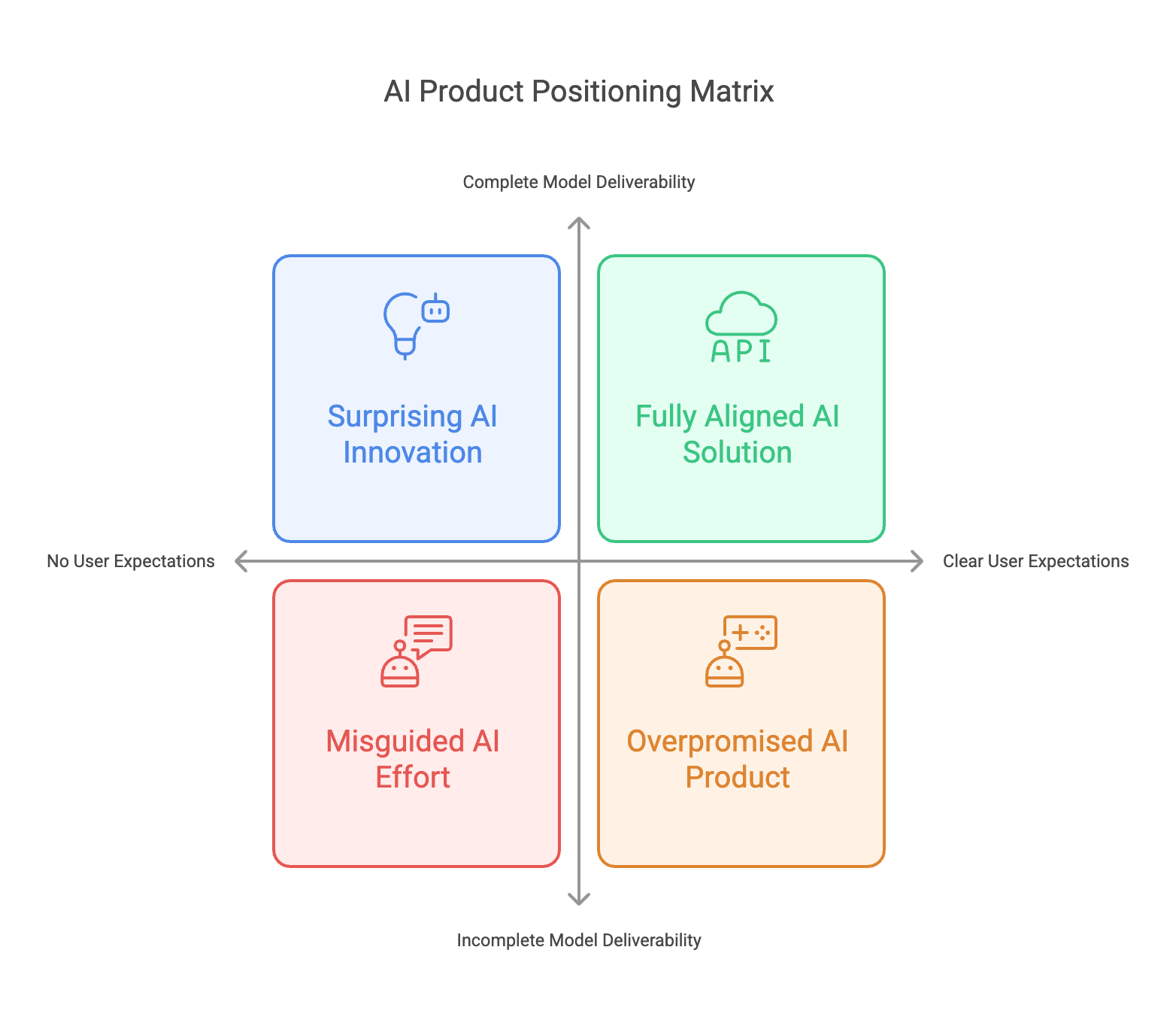
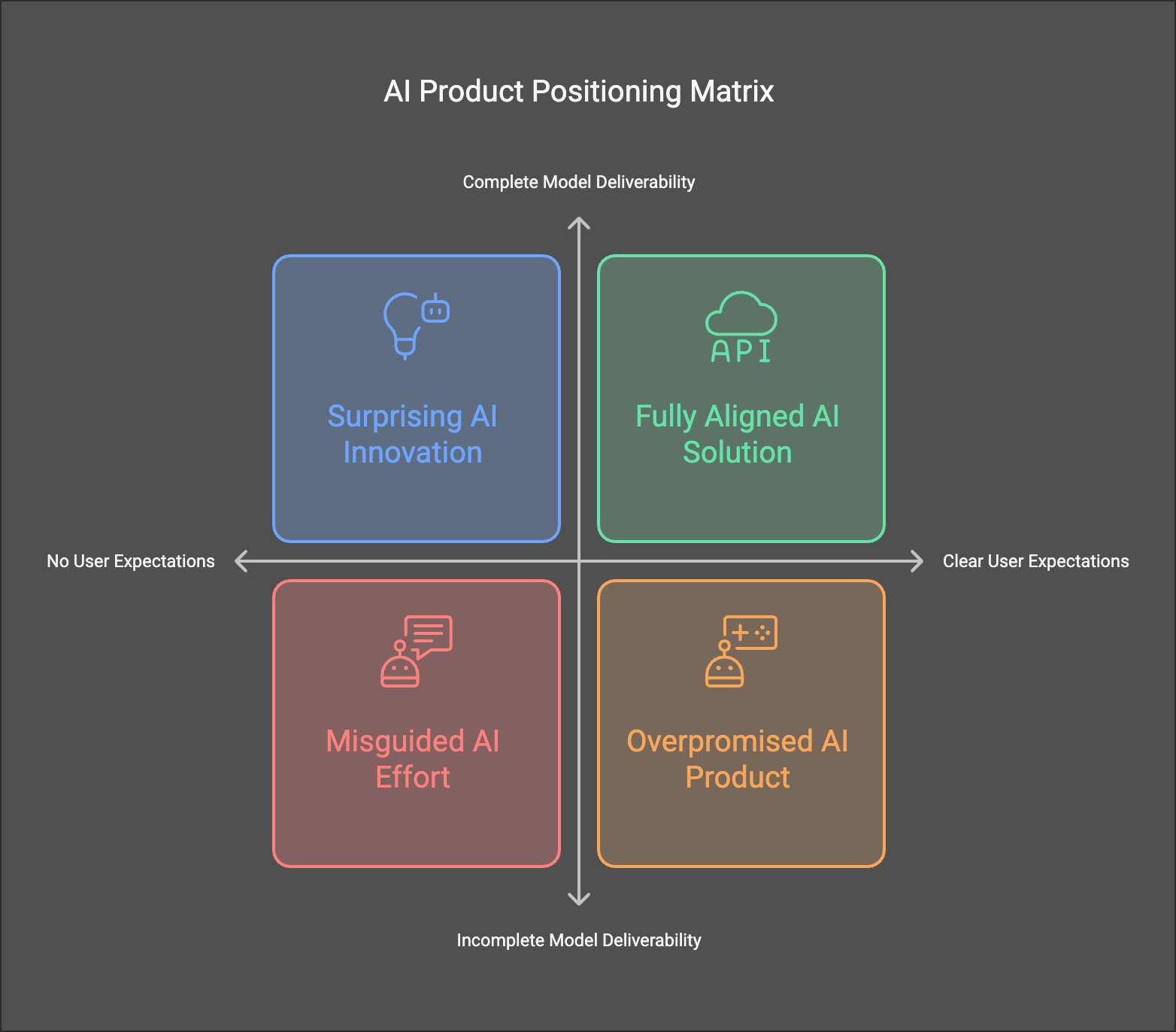
Combining these two dimensions results in four possible scenarios:
- Users Have Clear Expectations & Model Alone Can Deliver
- Users Have Clear Expectations & Model Alone Cannot Fully Deliver
- Users Have No Clear Expectations & Model Alone Can Deliver
- Users Have No Clear Expectations & Model Alone Cannot Fully Deliver
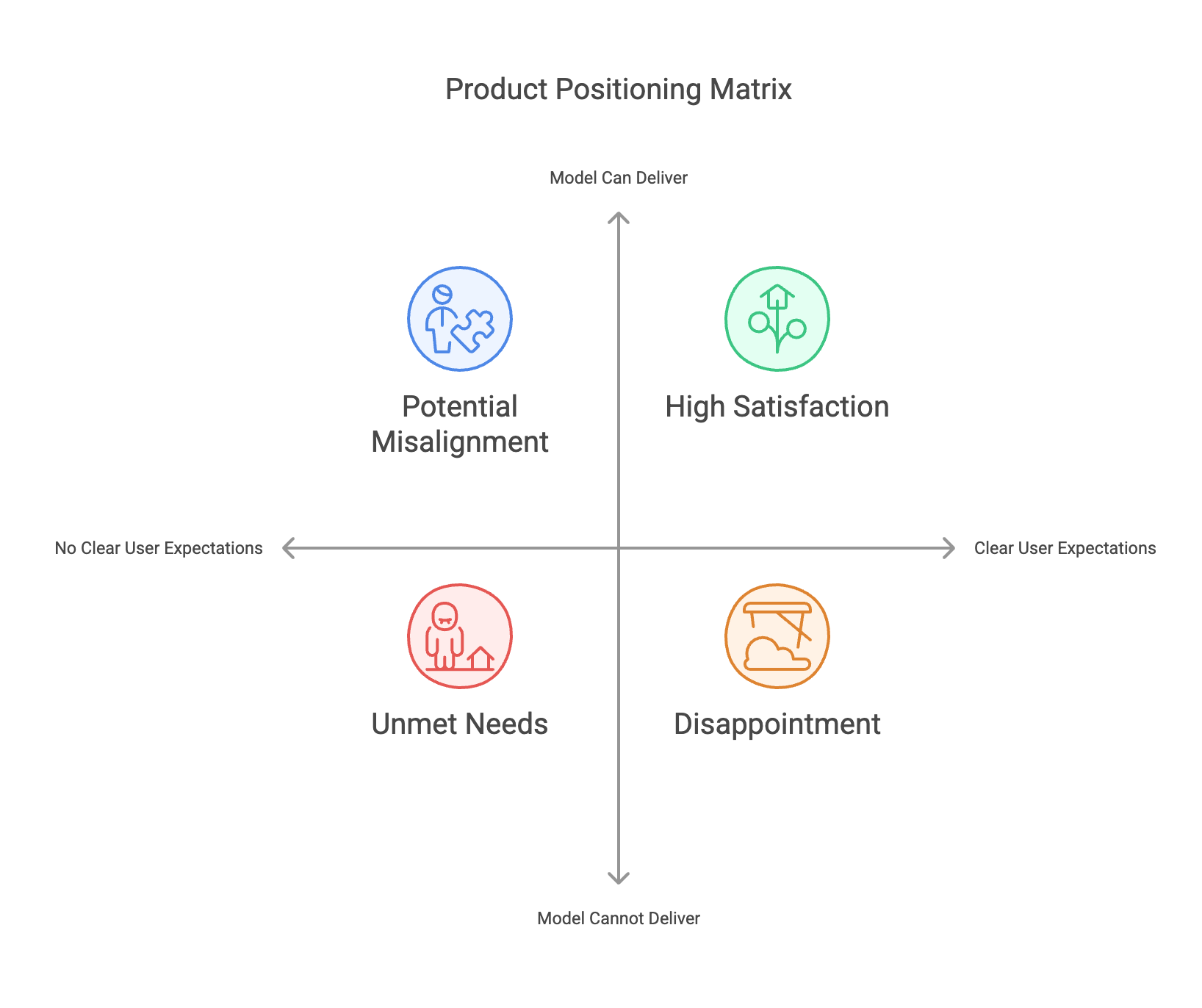
For a small AI company, the sweet spot often lies in a scenario where the evaluation complexity is manageable and user demand is well-defined. This makes it easier to set up precise benchmarks, collect feedback, and iterate effectively—ensuring the best return on limited resources.
Why Avoid Projects That Cannot Be Delivered by the Model Alone?
Many believe that “the real value lies in tasks that models alone cannot accomplish.” However, from a startup perspective, tackling such tasks typically requires extensive auxiliary systems, including complex data pipelines, human-in-the-loop review, or expert advisory boards. All of these requirements can slow your development cycle and increase operational costs—often outweighing any potential upsides. Instead, focusing on tasks where performance can be measured and improved quickly is usually more productive and cost-effective.
Why Evaluation Metrics Are Critical
1. Rapid Attribution and Improvement
Clear evaluation metrics enable teams to identify the root causes of performance gaps and make targeted improvements. For instance, in machine translation, commonly used metrics include BLEU or COMET scores. If performance in a specific area (e.g., medical documents) is lagging, you can collect more domain-specific training data, annotate specialized terminology, and refine your model accordingly.
- Attribution Example: If your system struggles with medical terminology, you can bring in subject-matter experts, collect high-quality annotated data, and focus on improving terminology translation.
2. Guiding User Behavior and Gathering High-Quality Data
Well-defined metrics help users better understand how the system functions and why certain outputs are generated. This understanding encourages more constructive feedback and data submission. For example, if your code-generation tool tracks “test pass rate” or “execution success,” users will be more inclined to provide detailed bug reports, ultimately feeding back into the improvement cycle.
3. Accelerating Iteration and Precision
Clear evaluation standards reduce time-to-iteration. In AI-based photo editing, for example, you might measure “realism” or “customer satisfaction” after each update. By comparing performance before and after changes, you can quickly determine which improvements work and which fall short, speeding up the refine-and-deploy cycle.
Designing Evaluation Metrics: From Simple to Complex
AI tasks vary in how easy or difficult they are to evaluate. Below is a spectrum from relatively simple, quantitative evaluations to highly specialized expert reviews.
1. Quantitative Evaluation
Suitable Examples:
- Machine Translation: BLEU, METEOR, COMET
- Question-Answering: Accuracy, F1-score, Exact Match (EM)
- Problem-Solving: Percentage of correct solutions, response time
- Code Generation: Test pass rates, execution speed, code readability
Key Advantages:
- Straightforward, automated scoring
- Quick iteration cycles
- Easy to perform A/B testing
This category typically involves tasks with well-defined “correct” answers or performance benchmarks, making it ideal for startups looking to iterate rapidly with minimal overhead.
2. Semi-Quantitative Evaluation
Suitable Examples:
- Photo Editing: User satisfaction surveys (e.g., Likert scales) or automated comparison of facial features to the original image
- Content Generation: User scoring of style, fluency, and coherence
Key Traits:
- Some level of subjectivity, requiring enough user data to mitigate individual biases
- Needs a system for quantifying subjective feedback (e.g., well-designed questionnaires)
- Typically longer evaluation cycles but can converge with large-scale user feedback
While elements like “aesthetics” or “tone” are inherently subjective, methodical user surveys and large sample sizes can yield surprisingly consistent metrics.
3. Expert-Level Evaluation
Suitable Examples:
- Medical Diagnosis: Requires specialist physicians or medical teams for accurate validation
- Legal Compliance: Must involve legal experts or in-house counsel
- Academic Research: Necessitates peer review by subject-matter experts
Key Traits:
- High cost due to the need for specialized professionals
- Slow iteration cycles
- Extensive domain knowledge needed for accurate assessments
For startups, expert-dependent tasks present a high barrier to entry. If you do pursue such domains, secure strong expert partnerships early on and be prepared for elevated costs and longer development timelines.
How to Apply: Practical Use Cases and Their Evaluations
- Machine Translation (MT)
- Metrics: BLEU, COMET, plus user surveys
- Advantages: Straightforward domain-specific fine-tuning (e.g., medical, legal, technical)
- Differentiation: Focus on specialized verticals for deeper accuracy and user satisfaction
- AI-Powered Photo Editing
- Metrics:
- Subjective scores (e.g., user satisfaction)
- Objective measures like PSNR or SSIM
- Advantages: Broad appeal, quickly adaptable via large-scale user feedback
- Differentiation: Tailor solutions to specific markets (wedding photography, e-commerce product photos)
- Metrics:
- Code Generation and Testing
- Metrics:
- Test pass rates
- Linting checks for code quality
- Advantages: Highly quantifiable, easy to conduct A/B tests and integrate with CI/CD pipelines
- Differentiation: Specialize in a specific language or framework for a dedicated user community
- Metrics:
- Automated Q&A and Content Generation
- Metrics:
- Accuracy, F1-score, Exact Match (EM)
- Crowdsourced or expert review for nuanced content
- Advantages: Flexible use cases (customer support, educational tools, marketing copy)
- Differentiation: Master one niche—e.g., finance, healthcare—to provide more trustworthy domain-specific responses
- Metrics:
Addressing the Concern of “Being Overtaken by Large Models”
A common worry is whether lightning-fast developments in large-scale AI models might instantly eclipse smaller startups’ products. In reality, AI applications extend beyond “just a model.” They integrate into complete, real-world solutions that cater to diverse user needs. Even as state-of-the-art models evolve, there remain clear opportunities for startups to differentiate:
- Varied Needs Across Domains
- Specialized content or translation for business, academic, or technical fields
- Unique user preferences for styling or formatting
- In-Depth Vertical Market Solutions
- Industry-focused enhancements for healthcare, education, or finance
- Domain-specific resources, offline services, and consulting that create higher entry barriers
- Customized Competitive Edge
- Proprietary domain expertise and user data
- Tailored pipelines that incorporate features such as ongoing reviews or real-time updates
- Ecosystem integration (APIs, partner networks) that further fortify market position
The real value for a small AI company lies in how effectively it can shape, implement, and iterate models around tangible user problems—backed by robust evaluation pipelines.
Conclusion and Recommendations
- Prioritize Tasks with Well-Defined, Easily Measurable Metrics
- Shorter development cycles and more precise feedback
- Stronger alignment with real user needs
- Focus on Scenarios Where Users Have Clear Expectations
- Clarity drives better metrics and more actionable feedback
- Users are more likely to collaborate and test improvements
- Leverage Scientific Evaluation Mechanisms to Enhance Product Value
- Evaluation feeds attribution, leading to targeted improvements and valuable data
- This virtuous cycle underpins sustainable product growth
- Capitalize on Vertical Niches for Differentiation
- Harness domain experts and niche knowledge to deliver premium-level solutions
- Build a moat with specialized expertise to avoid direct competition with large, general-purpose models
- Adopt a Service-Centric Mindset—Not Just a Purely Model-Driven Approach
- Offer additional professional services, such as data cleansing and analysis
- Position the model as one component of a broader solution ecosystem
Ultimately, a well-structured evaluation process is the bedrock for any AI startup looking to scale effectively. It paves the way for clear attribution, targeted improvements, and the collection of new, high-quality data. When combined with a strategic focus on niche domains, AI startups can carve out substantial competitive advantages—even in the face of rapidly advancing large-scale models. By anchoring each step in rigorous, transparent metrics, smaller companies can quickly adapt, refine their offerings, and thrive in today’s dynamic AI landscape.