Navigating AI Cost, Latency, and Quality: Lessons from DeepSeek

The shifting landscape of AI—especially in large language models (LLMs)—is upending many assumptions about cost, performance, and market strategy. From my own “Build in Public” journey prototyping new products, to observing DeepSeek’s latest breakthroughs in model efficiency, here are some reflections and insights for indie hackers, creators, and startup leaders navigating this rapidly evolving space.
1. Quick Primer: DeepSeek V3 vs. R1
DeepSeek V3 is the core large-scale model built with a Mixture-of-Experts (MoE) architecture (671B parameters in total, but with only 37B “activated” at a time). It focuses on delivering broad coverage at a lower cost by selectively using specialized “experts.” This yields dramatic reductions in training and inference costs compared to equivalent “dense” LLMs, albeit sometimes at the expense of more generalized or creative tasks.
DeepSeek R1, on the other hand, is a specialized reasoning model—essentially a “Chain-of-Thought” (CoT) system that showcases advanced problem-solving abilities in math, logic, and programming. R1’s step-by-step reasoning emerges from reinforcement learning techniques with minimal human intervention, resulting in robust performance on code and math tasks. Moreover, it comes with a provocative price point for inference (under $3 per million tokens in many scenarios), radically undercutting more established solutions.
Why it Matters:
- Price: DeepSeek’s approach highlights that MoE and advanced reinforcement learning can slash costs. Indie hackers or small teams who previously feared LLM usage costs might now see workable price/performance trade-offs.
- Latency & Scale: Combining large MoE models for training with a specialized reasoning model for inference is attractive for production scenarios where speed and cost go hand in hand.
- Quality: R1 excels in structured problem-solving. V3 offers broader coverage with some trade-offs in open-ended creativity. Each model has distinct sweet spots—understanding that difference is vital if you want to plug these APIs into your product.
2. AI Product Market Impact: Costs, Margins, and Strategic Tensions
A. Squeezing Margins with High-Cost APIs
One of my “Build in Public” projects, Pictotales, leverages a multi-modal audio generation API capable of producing expressive, emotionally nuanced voices directly from text or audio prompts. The challenge? These advanced capabilities often come with a higher price tag. Providers tend to charge a premium for the complex computational pipelines required to detect tone, inflection, and other nuances within the input—costs that can quickly erode margins for indie hackers or small startups if they can’t offset them with sufficient revenue or a higher-priced offering.
That cost structure erodes margins for small teams. If you can’t justify a higher subscription price for your product, you’re effectively locked out of the more sophisticated AI features that might differentiate you. This tension between user willingness to pay and the underlying API costs is a recurring theme for startups.
B. Latency + Human Labor Economics
Any AI solution that costs more—or takes longer—than simply hiring a human is destined for slow adoption. Historically, STT → LLM → TTS solutions were either too expensive or introduced time lag. But when inference costs plummet and throughput improves (as we’re seeing with models like DeepSeek R1), fully automated conversation loops become cheaper than human labor. That’s a turning point.
Even large enterprises—often sluggish to adopt new tech—will accelerate integration once the cost-per-interaction undercuts in-house call center or customer service staff. In short, when AI inference cost < labor cost, mass adoption is practically inevitable.
C. Disrupting Giant LLM Strategies
The original strategy among LLM heavyweights was to train huge high-reasoning teacher models (like Open AI O3 or Claude Sonnet 3.5) and then distill them into smaller, cheaper, specialized “student” models (O3-mini or Claude Haiku 3.5) or MoE ensembles. Now DeepSeek’s engineering breakthroughs in model compression, cost-effective MoE, and open-source reasoning algorithms challenge that top-down approach. Competitors may have to:
- Reassess where to focus R&D (pure scale vs. engineering optimizations).
- Adjust pricing to defend market share against cheaper, open models.
- Release smaller, specialized versions more quickly rather than gating them behind large teacher models.
We could soon see a “race to the bottom” on inference costs and new, creative bundling of advanced features to justify premium subscriptions.
3. Building in Public: Lessons from My Own Experiments
As I build Pictotales in public, I constantly juggle:
- Feature Depth vs. Cost: Do we integrate advanced emotional TTS now, or wait until we can negotiate better per-token rates or adopt a more cost-efficient open-source solution?
- Speed to Market vs. Budget Restraints: Early adopters might love a polished voice-based feature, but if the usage cost eats away at our runway, that short-term “wow factor” could become unsustainable.
- Iterative Feedback: By sharing product updates in real time—MVP prototypes, user experiments, performance metrics—I can gauge actual demand for high-fidelity audio or advanced reasoning before committing to large-scale licensing deals.
The “Build in Public” approach also opens doors to community-led solutions. For instance, if a user or contributor can integrate a cheaper open-source TTS library or a local inference engine for the audio portion, we slash overhead and gain more control over the voice “brand” of Pictotales.
4. Economic Theory and the Convergence of Cost & Value
It’s worth grounding these dynamics in basic economic principles:
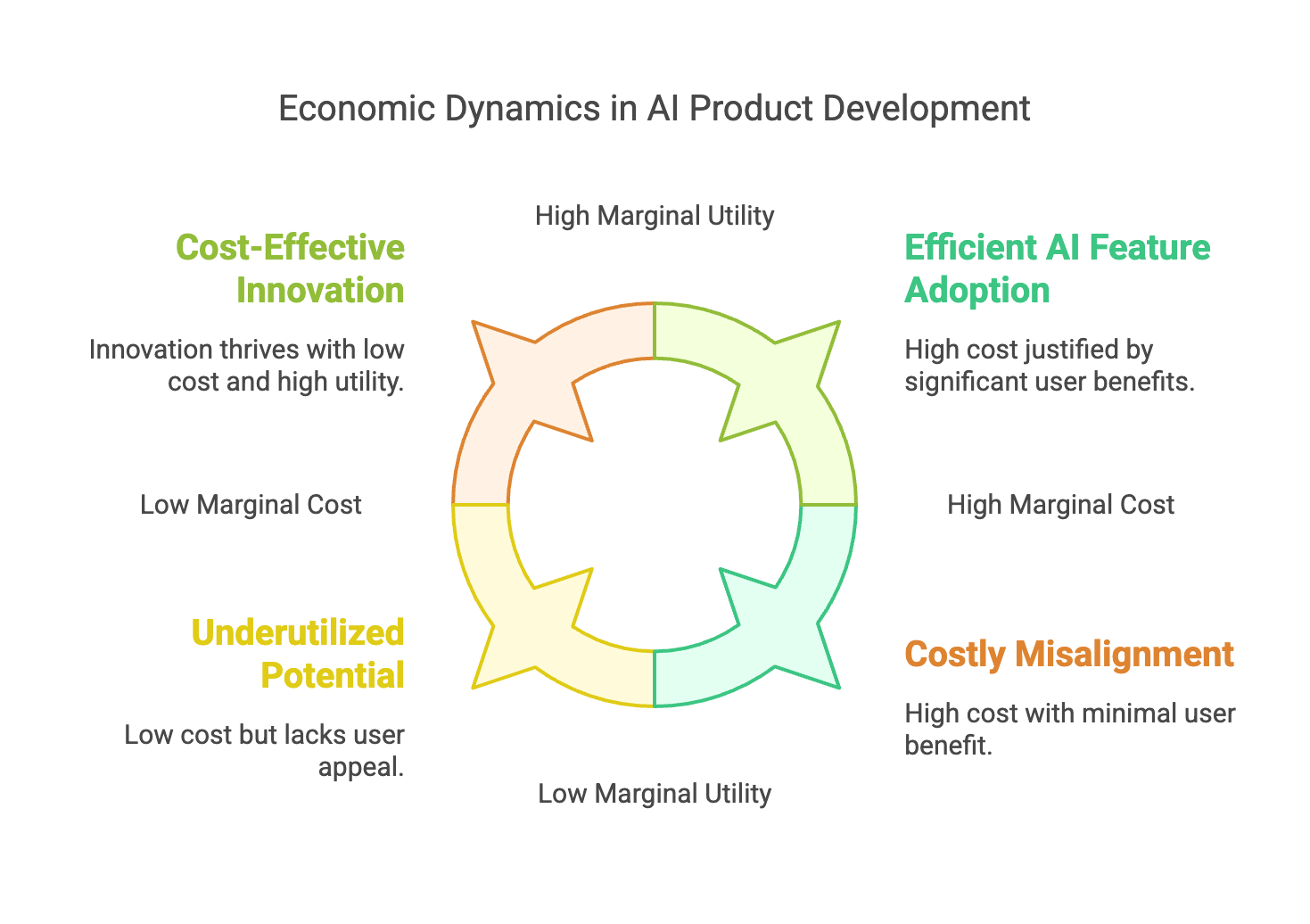
- Marginal Cost vs. Marginal Utility: If the marginal utility (i.e., tangible user benefit or willingness to pay) of advanced AI features doesn’t exceed the marginal cost (per token or per request), your product’s growth stalls.
- Supply Expansion through Efficiency: As engineering efficiencies (like MoE or Knowledge Distillation) drive down costs, supply of “reasoning power” increases. Lower price → higher usage → further refinements.
- Disruption Through Commoditization: If advanced LLM functionality becomes “commoditized” (akin to a utility), the real differentiation moves to specialized layers: domain adaptation, unique data, or integrated experiences (e.g., real-time voice pipelines).
In simpler terms: Cost leadership often wins the initial wave of mass adoption, while premium features stand out only if they justify their higher price in a clear, ROI-driven use case.
5. Shifts in Deployment and Pricing Tactics
With DeepSeek’s example, we see how quickly “secret sauce” can be overturned by open-source innovation. Proprietary giants may respond by:
- Tiered Offerings: Splitting user segments into “basic, mass-usage models” vs. “top-tier creative or reasoning models” with premium rates.
- Engine Customization: Offering dedicated, cost-optimized versions for enterprise clients who can pay for specialized training while keeping a cheaper general version for broader markets.
- Rapid Distillation Pipelines: Accelerating new, smaller spinoff models that can be updated swiftly to maintain competitive cost/performance ratios.
Any model that consistently slashes price or drastically improves speed stands to grab mindshare from incumbents. Competition among providers will likely intensify, creating more “AWS vs. Azure vs. GCP” style pricing wars—only now in the LLM domain.
6. Opportunities & Insights for Indie Hackers
For indie hackers, all these shifts can be a major opportunity:
- Build Nimble, Build Niche: You don’t need a trillion-parameter model to compete. You might focus on a specialized domain (e.g., educational math tutoring, supercharged documentation Q&A, or expressive storytelling) and leverage cheaper specialized LLM APIs or open-source local inference.
- Value > Hype: Avoid features that are purely for show. Instead, solve a real pain point—like reducing call center costs or accelerating data analysis—to justify any added AI expense.
- Own the User Experience: As LLM capabilities commoditize, your brand, user interface, and integrated workflow will be the primary differentiators. If you control your users’ complete experience, you can slot in whichever AI model is fastest or cheapest without them noticing.
- Follow the Pricing Tides: Keep track of how big providers (and new entrants like DeepSeek) keep adjusting their token prices or free tiers. If a certain model slashes inference costs, pivot quickly to seize that advantage.
- Experiment Publicly and Often: By sharing your progress, from MVP designs to real usage metrics, you attract early feedback and potential collaborators. This not only shapes product-market fit but keeps you aware of new open-source breakthroughs or cost-saving techniques that arise literally every week.
Final Thoughts
AI progress moves faster than ever, and we’re at a moment where decreased inference latency and falling per-token costs can spark radical adoption across industries. For startups and indie hackers, the message is clear: seize efficiency gains, align your value proposition with the new economics, and stay agile in choosing or swapping out LLM providers.
From DeepSeek V3’s engineering feats to R1’s specialized reasoning, we see how cost, latency, and model design transform an entire market. While big players maneuver to protect their leads, smaller creators—armed with a “Build in Public” mentality—can swiftly adapt, reduce overhead, and deliver targeted solutions that resonate with real-world needs. In the end, the best product strategy fuses cutting-edge AI with smart economics—helping you stand out in a crowded market and sustainably serve the people who matter most: your users.
Anyway, just wrote a silly child story about Thinking, Fast and Slow by Daniel Kahneman with Pictotales.

Thanks for following along on my own Build in Public journey. I hope these reflections spark a few new ideas for your projects. If you have any thoughts or want to share your own experiences, drop a comment or connect with me on social media. Let’s keep building together—innovating boldly while staying anchored in the realities of cost and user value.